 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
May 22, 2026Large language model (LLM) agents accumulate rich episodic trajectories while solving real-world tasks, but it remains unclear whether such experience can be distilled into reusable procedural skills. We introduce SkillEvolBench, a diagnostic benchmark for evaluating this step from experience reuse to skill formation. It contains 180 tasks across six real-world agent environments, organized into role-conditioned task families with shared latent procedures. Agents learn from acquisition tasks, update an external skill library using compacted trajectories and verifier feedback, and then face frozen deployment tasks testing context shift, adversarial shortcuts, and composition. By comparing self-generated and curated-start skill evolution against no-skill and raw-trajectory controls, SkillEvolBench separates procedural abstraction from base capability, curated prior knowledge, and direct reuse of episodic traces. Across ten model configurations and three agent harnesses, we find that current agents often adapt locally but rarely form robust reusable skills. Skill-based conditions can improve acquisition or replay, and individual models sometimes gain on specific deployment axes, but these gains are unstable under frozen deployment. Raw-trajectory reuse frequently outperforms distilled skills, suggesting that current abstraction procedures discard contextual and procedural cues that remain useful for future tasks. Capacity and cost analyses further show that writing more skills or larger Tier-3 resource libraries is not sufficient: additional updates can improve coverage while introducing episode-specific drift and procedural clutter. These findings position SkillEvolBench as a testbed for measuring when one-off experience becomes durable procedural knowledge rather than task-local memory.
DSDR: Dual-Scale Diversity Regularization for Exploration in LLM Reasoning
Feb 23, 2026Reinforcement learning with verifiers (RLVR) is a central paradigm for improving large language model (LLM) reasoning, yet existing methods often suffer from limited exploration. Policies tend to collapse onto a few reasoning patterns and prematurely stop deep exploration, while conventional entropy regularization introduces only local stochasticity and fails to induce meaningful path-level diversity, leading to weak and unstable learning signals in group-based policy optimization. We propose DSDR, a Dual-Scale Diversity Regularization reinforcement learning framework that decomposes diversity in LLM reasoning into global and coupling components. Globally, DSDR promotes diversity among correct reasoning trajectories to explore distinct solution modes. Locally, it applies a length-invariant, token-level entropy regularization restricted to correct trajectories, preventing entropy collapse within each mode while preserving correctness. The two scales are coupled through a global-to-local allocation mechanism that emphasizes local regularization for more distinctive correct trajectories. We provide theoretical support showing that DSDR preserves optimal correctness under bounded regularization, sustains informative learning signals in group-based optimization, and yields a principled global-to-local coupling rule. Experiments on multiple reasoning benchmarks demonstrate consistent improvements in accuracy and pass@k, highlighting the importance of dual-scale diversity for deep exploration in RLVR. Code is available at https://github.com/SUSTechBruce/DSDR.
MMDeepResearch-Bench: A Benchmark for Multimodal Deep Research Agents
Jan 18, 2026Deep Research Agents (DRAs) generate citation-rich reports via multi-step search and synthesis, yet existing benchmarks mainly target text-only settings or short-form multimodal QA, missing end-to-end multimodal evidence use. We introduce MMDeepResearch-Bench (MMDR-Bench), a benchmark of 140 expert-crafted tasks across 21 domains, where each task provides an image-text bundle to evaluate multimodal understanding and citation-grounded report generation. Compared to prior setups, MMDR-Bench emphasizes report-style synthesis with explicit evidence use, where models must connect visual artifacts to sourced claims and maintain consistency across narrative, citations, and visual references. We further propose a unified, interpretable evaluation pipeline: Formula-LLM Adaptive Evaluation (FLAE) for report quality, Trustworthy Retrieval-Aligned Citation Evaluation (TRACE) for citation-grounded evidence alignment, and Multimodal Support-Aligned Integrity Check (MOSAIC) for text-visual integrity, each producing fine-grained signals that support error diagnosis beyond a single overall score. Experiments across 25 state-of-the-art models reveal systematic trade-offs between generation quality, citation discipline, and multimodal grounding, highlighting that strong prose alone does not guarantee faithful evidence use and that multimodal integrity remains a key bottleneck for deep research agents.
Unsupervised Deep Unrolled Reconstruction Using Regularization by Denoising
May 07, 2022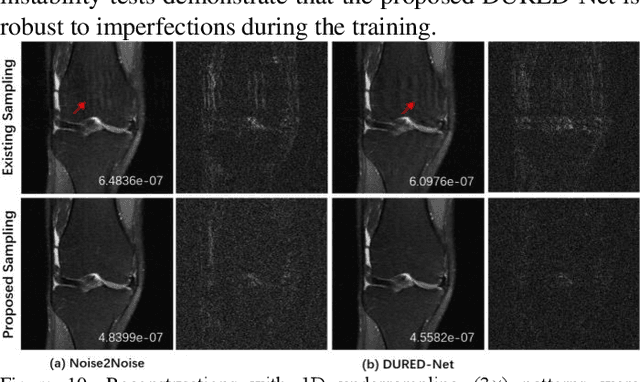
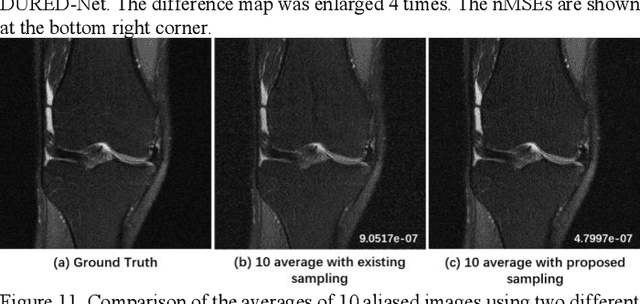
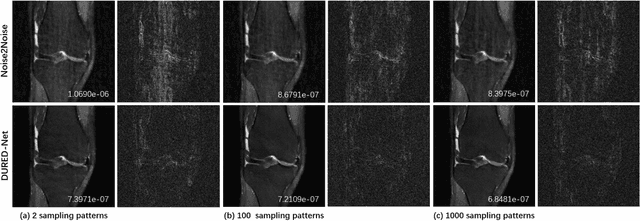
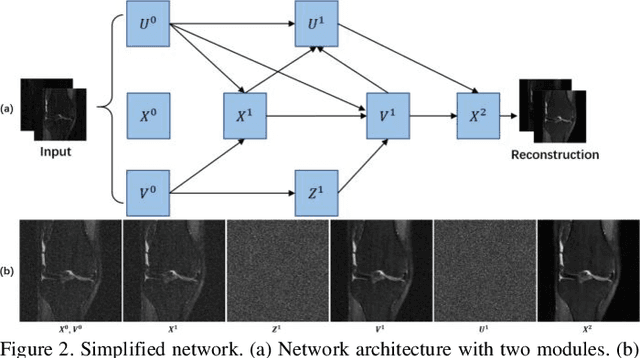
Deep learning methods have been successfully used in various computer vision tasks. Inspired by that success, deep learning has been explored in magnetic resonance imaging (MRI) reconstruction. In particular, integrating deep learning and model-based optimization methods has shown considerable advantages. However, a large amount of labeled training data is typically needed for high reconstruction quality, which is challenging for some MRI applications. In this paper, we propose a novel reconstruction method, named DURED-Net, that enables interpretable unsupervised learning for MR image reconstruction by combining an unsupervised denoising network and a plug-and-play method. We aim to boost the reconstruction performance of unsupervised learning by adding an explicit prior that utilizes imaging physics. Specifically, the leverage of a denoising network for MRI reconstruction is achieved using Regularization by Denoising (RED). Experiment results demonstrate that the proposed method requires a reduced amount of training data to achieve high reconstruction quality.